

一、互联网与世界的比特镜像
我曾经和很多朋友探讨过一个很朴素的问题,在你的眼中,互联网是什么?
要回答这个问题,必须先回答另一个问题,互联网为什么而出现?
在我看来,这个世界是由三个要素构成的,也即是物质、能量、信息。
那么什么是信息呢?
按照信息学祖师爷CE Shannon在《信息论》里给的定义:
信息是对事物的运动状态与存在方式不确定的描述。
人类获取信息的过程就是消除不确定性的过程。因为描述信息混乱与不确定性的概念是“信息熵”,所以你也可以把人类获取信息的的这个过程看做是一个“信息熵减”的过程。
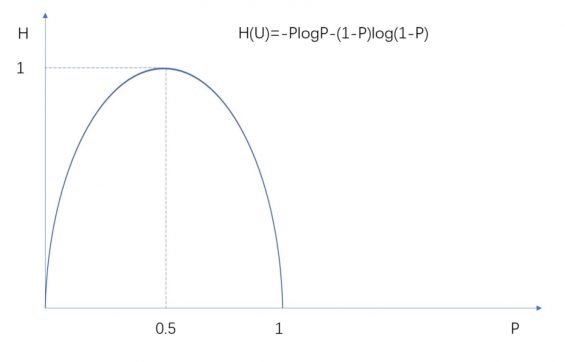
二元信源的信息熵
换成人话说就是:获取信息能够让你从“不明白”到“明白了”。
人类为了在这个世界生存下来,我们的基因把我们“设计”成了一个高效的信息获取与处理信息的系统。比如,我们(或者说所有的灵长类)进化出了色彩识别的能力,我们的眼球能够识别380~780nm波段范围的光谱,这让我们拥有可以通过色彩分辨食物、寻找掩体、感知危险的能力。
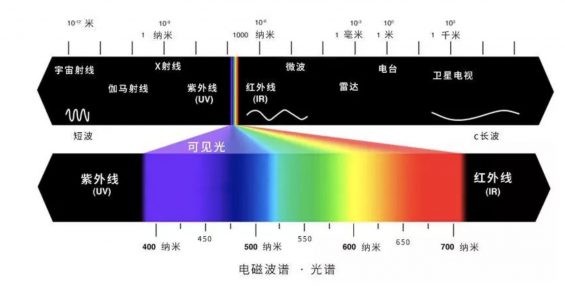
当然,这还只是非常基础的信息获取能力。在人类数百万年的演化过程中,为了满足我们社会组织的需要,我们进化出了更复杂高级的对抽象信息的获取与理解的能力,也就是对文字、图画、音乐等信息的处理能力。
简单说,获取信息对我们很重要,但这和互联网又有什么关系呢?
这里我们还需要理解两个概念:一个是信号,一个是信道。

信息的传递
信息发布者(信源)发布了一个信息,这个信息以某些物理介质承载(这就是信号),通过媒介传递了出去(这就是信道)快手天津女,被信息的接受者接收(信宿)。
举个栗子:
你说了一句话(这句话包含的就是信息),这句话转化成了音波信号,通过空气这个信道媒介传到了我这里,被我听到了,这就是个信息传递的过程。
这个过程里,信道中会有“噪音”,噪音会干扰信号,信息传递就会出现偏差,最后甚至会导致信息传递失败。所以,不同的信号承载形式和不同的信道会有相对的信息传递的物理极限。比如,你在1公里外说了一句话,我可能就听不到了。
因此,信号能够不受干扰的传递距离,对我们能维系多大的社会组织效率产生了很大的影响。
为了最大程度保存信号不受干扰,尽可能远距离传递/获取信息,我们人类发明了各种科技。迄今为止,传递信息的最先进的科技工具是“互联网”。
以上内容,如果你在大学本科读过信息学的话,基本上第一课就讲这个。
但如果只理解到工具的层面,我们对互联网的理解就不够深刻。因为互联网传递信息的时候,并非单向传递。
实际上,互联网保留了现实世界让每个人发布和获取信息的能力。因此,互联网形成了一个“网络”。这个网络在尽可能提取这个世界上已知的所有具象客观和抽象主观的信息,把这些信息映射到互联网上,然后以电信号(光速)传递这些信息。
所以,我经常说,互联网是现实世界的比特(BIT,信息的单位)镜像。
而且,这个比特镜像上信息是以“光速”运转传递的。
S=V*T
我们都知道这个简单的公式,意思就是“距离=速度*时间”。简单来说就是,如果信息以光速的速度在传递,那么在同样的时间里,我们获取信息的半径距离就非常长。
长到什么程度呢?
你肯定听过“地球村”这个概念,在互联网刚传进中国的那十年里,人们特别喜欢说这个概念。虽然有点土,但这句话确实很形象——地球变成了个村。
一开始这挺好的,我们获取信息的半径扩大了,我们用计算机和互联网完成了一次“进化”。但我们其实不一定能够习惯这种变化,因为人类面对的环境从文明诞生的1万年来,第一次从“信息匮乏”变成了“信息过载”。
互联网的发展过程,我们可以梳理出两个主脉络,分别是:
网络上的信息越来越多;上网的人越来越多。
这两条主脉络本身又互相促进构成了一个闭环,也就是越来越多的人上网制造、发布、卷入了越来越多的信息到互联网上,互联网上的信息越来越多,也吸引越来越多的人去使用它。
我们都知道,到2019年的时候,全球的网民的数量大概正好是40亿出头,其中大概有不到9亿是中国网民。
那么,你知道互联网上一共有多少信息吗?
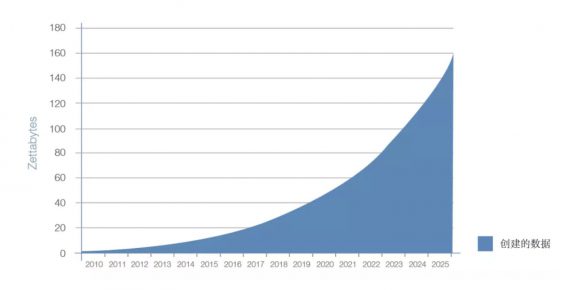
数据来源:IDC,2017年《数据时代2025》白皮书
2017年的时候,IDC(国际数据公司)做过一次研究,他们估计当时互联网上的信息大概20多个ZB(1ZB=1万亿GB);当时预测这个数据到2019年大概会翻一倍,达到40个ZB。
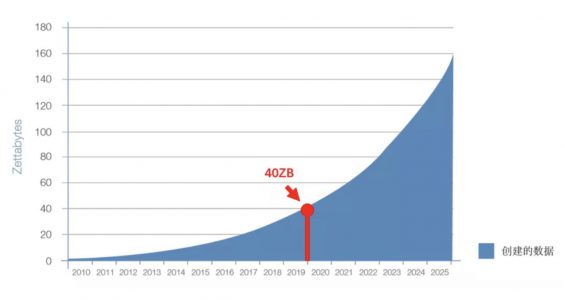
2019年的全球数据量
粗略计算一下,每个网民理论上平均被分配到1ZB的信息。当然,实际情况并不是平均主义,这里只是便于理解。
我只想说,即便我们行使这样的平均主义,你依旧没可能在你短暂的一生里,把这些信息都完整地接受一遍。更何况,在可以被重复消费的信息海洋里,今天的你终其一生在40ZB的信息海域里找的,不过是需要的那几十个TB而已。
你能获取的信息超过了你能处理的信息的上限,这就是信息过载。
互联网的先驱其实很早就意识到这个问题了。

世界上第一个网站
万维网(WWW)之父Tim Berners-Lee,他发明了万维网,与此同时,他也发布了世界上的第一个网站()。这个网站用超文本(hypertext)技术把CERN(欧洲核子研究中心)各个实验室连接起来,因为用了超文本(也就是后来的链接),所以人们可以方便地浏览聚合的信息。
1991年8月6日,Tim Berners-Lee公开了这个项目,这一天也被认为是万维网的诞生。这个网站介绍了超文本的规范、网站的建站细节、浏览器的安装使用等信息,后来这个网站还收录了一些其他的网站范例,所以也被认为是世界上第一个网站目录。
也是从这一天起,每个接入万维网的人(或者说,你熟悉的因特网),都有获得建立一个属于自己的图形化网站和对应的http网址的权力。采用更自然的拼写的http网址,已经比之前的FTP地址要容易访问得多。
当然,在万维网诞生的时代,尽管Tim Berners-Lee已经试着去做一些万维网站的目录工作。但http网址在后来发生如此巨大的爆炸式增长,以至于这个工作显然已经需要专门的机构来服务。
所以,从那个时代开始,互联网信息分发漫漫之路就被开启了。
我们大概可以把互联网信息分发的模式,按照其主导的信息分发的模式流行的时期,大致划分成四个时代:
分类索引-门户时代;搜索引擎-搜索时代;订阅关注-SNS时代;推荐算法-Feed时代。
在这四个时代以外,还并行了一个长期存在的“高热更新-社区热帖”模式(这个模式在国内因为百度贴吧在搜索时代的崛起,一度也成为了非常重要的一种信息分发模式)。
有必要注意的是,以上的这些时代所诞生的信息分发模式,大多都随着相应的技术变革应用所产生,背后又都伴随了商业模式的彻底升级革新,兴起并主导了一个网络时代。
这些信息分发模式的演化塑造了不同时代的互联网巨头,不过,这些模式也并非完全的先后替代。更多的是新的信息分发模式向下兼容了早期的模式,通过商业模式的创新,后者主导的企业把前辈按在了地上摩擦(至少也是某种程度上打破了前辈的领导者地位)。
二、分类索引-门户时代 & 搜索引擎-搜索时代
虽然BBS论坛和搜索引擎技术诞生的时间都要比万维网诞生还早一些,但基于生产力的应用需要适应时代发展的客观规律。
万维网诞生初期,主导网络世界信息分发的并不是搜索引擎技术和BBS论坛,而是基于超文本技术的分类索引。
尽管第一个互联网分类索引服务并不是Yahoo,不过最知名与成功的案例确实是它。

1994年第一版的Yahoo!
这个由华裔企业家杨致远创立的网站,用高效的管理、激进的市场策略,在上世纪90年代中期快速击败了他的主要对手成为了全球最重要的网络门户(没错,国内曾经的四大门户——新浪、搜狐、网易、腾讯,最初都是Yahoo!的copycat)。所谓“门户”这个概念,对于现在的年轻人来说可能有些陌生。但对于当时的人来说,这个词汇是很形象的描绘,这是大多数人上网的第一步。
今天的人可能很难想象,在25年前万维网刚诞生不久没有搜索引擎的年代,如果人们要寻找什么“信息”,人们该如何开始开始。所以,Yahoo!这个由手工归纳分类,手工录入搜集的分类检索目录网站,就是你能最快捷发现又有什么新的网站出现在互联网上的地方。
你可以把这类网站看做“黄页”,或者从某种程度上说,Yahoo!就是网络黄页(马云最早想做网络黄页,后来又拿了杨致远的投资,不是毫无理由的)。
人类的想象力并不是无中生有的快手天津女,我们总是会基于已有的一些事物,结合一些变化的趋势,做出对未来的做一些猜想。对于从未见过当今这个未来的人来说,把聚合所有网址信息的网站,参照已经存在的电话黄页,“拟物化”的设计产品,是再合理不过的事情。
而Yahoo!的商业模式可以说非常粗暴简单,就是贩卖广告,准确地说是贩卖网站上的banner广告。

1997年的Yahoo!搜索框上方明显的汽车banner广告
当时的Yahoo!想要增加收入,方法也很简单,就是在首页上(包括后来的各个索引目录页面的大分类页面)上增加banner广告位(增加Ad Loads),并且把单个广告卖得更昂贵(提升Ad Price)。为此,Yahoo!愿意给广告销售极高的提成,同时大量投放市场广告,以此激励销售与教育广告主。

2002年的Yahoo!首页上一堆广告banner
早期的Yahoo!在做分类索引的信息分发模式大成功之后,快速进化了产品的形态。
首先,在1995年加入了搜索功能。不过这个搜索和后来的搜索引擎还不太一样,主要是用来做分类检索的快捷搜索的,搜索出来的结果往往直接指向某个网址(这个细节待会儿在讲搜索引擎时格外重要)。
然后96年Yahoo!又开始了邮箱服务,再然后是把业务触角扩张到新闻资讯服务(这项服务等于对标了传媒报纸的业务)。
作为当时全球最大的互联网门户、网络目录、电子邮箱和新闻资讯网站,伴随快速增长的全球网民数量,雅虎市值一度超过1000亿美金。以至于今天的Google和中国的四大门户,总有Yahoo!的既视感。
然后,在未来终结门户时代的搜索引擎登场了。
严格地说,搜索引擎技术的诞生要比万维网还早一年,现代搜索引擎的前身是诞生于90年的Archie,一种通过文件名从FTP主机中查找文件的技术。
而到了1994年,第一款现代意义上使用了蜘蛛爬虫技术的搜索引擎Lycos诞生了(Lycos这个词就是一种狼蛛的名字)。4年后,我们熟悉的Google也诞生了。
这些搜索引擎和分类索引的门户,最初的差异就是获取网络信息的方式不同。分类索引用人工录入的方式,而搜索引擎则使用蜘蛛爬虫程序全自动爬取信息。另外,人工分类的目录主要收录的是网址,而蜘蛛爬虫爬取的可以是每个具体的网页。
对于使用者来说,前者需要进入网站自己继续找信息;后者可以一步到位,方便快捷。
显而易见,搜索引擎获取网络信息的效率要比分类索引高得多。
那么,为什么一开始人们并不那么爱用搜索引擎呢?
因为早期的搜索引擎虽然可以爬到很多东西,但在大量的相关结果中,搜索引擎并不能准确“猜到”哪个才是你要的结果。
Google之所以快速崛起的原因,不仅仅是因为他们孜孜不倦地快速爬取网页或者是产品的简洁设计。
早期的胜负手来自Google创造性地重新定义了搜索结果的排序方式。
Google的两位创始人之一,Larry Page发明了PageRank算法,通过指向网页的链接数量来衡量一个网页的价值。Google在搜索结果的优化上发力,这让他们独树一帜。
实际上,包括PageRank算法和后来他们不断加入的Hilitop算法、HITS算法、TrustRank算法以及用来处理一些不良网页的SandBox(沙盒)等技术,让Google成为了2000年左右
来源【抖音特训营】自媒体,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站不拥有所有权,不承担相关法律责任。如发现有侵权/违规的内容, 联系邮箱jkhui22@126.com,本站将立刻删除。