

在日常工作中,很多时候都会用到数据分析的方法,聚类模型模型看起来非常简单,但实际上它的十分重要;本文作者分享了关于如何用聚类模型做数据分析的方法,我们一起来学习一下。
k-means属于无监督学习算法,无监督算法的内涵是观察无标签数据集自动发现隐藏结构和层次,在无标签数据中寻找隐藏规律。
聚类模型在数据分析当中的应用:既可以作为一个单独过程,用于寻找数据内在规律,也可以作为分类等其他分析任务的前置探索。
例如:我们想探寻我们产品站内都有哪些社交行为群体,刚开始拍脑门想可能并不会很容易。
这时候可以根据用户属性、行为对用户进行聚类,根据结果将每个簇定义为一类社交群体,基于这些类训练后续的分类模型,给用户打标签后进行个性化推荐、运营。
一、k-means算法与距离
K-means聚类的目标,是将n个观测数据点按照一定标准划分到k个聚类中,数据点根据相似度划分。每一个聚类有一个质心,质心是对聚类中所有点的位置求平均值得到的点k9438手机直播中心开奖结果,每个观测点属于距离它最近的质心所代表的聚类。
模型最终会选择n个观测点到所属聚类质心距离平方和(损失函数)最小的聚类方式作为模型输出,K-means聚类分析中,特征变量需要是数值变量,以便于计算距离。
我们使用距离来测量两个样本的相似性,距离的实质是他将两个具有多维特征数据的样本的比较映射成一个数字,可以通过这个数字的大小来衡量距离。
几个常见距离计算方法:
欧几里得距离-直线距离,不适合高维度数据,对某一维度大数值差异更加敏感;曼哈顿距离-也叫出租车距离,用来标明两个点在标准坐标系上的绝对轴距总和,只计算水平或垂直距离,对某一维度大数值差异不敏感;Hamming距离-可用来测量含有分类值的向量之间的距离;余弦距离-通过计算两个向量的夹角余弦值来评估相似度,适用于结果与数据中特征的取值大小无关,而与不同特征之间比值有关的案例。
k-means的实质是每次都把质心移动到群内所有点的‘means’上,不是建立在距离这个基础上,而是建立在最小化方差和的基础上,方差恰好是欧几里得距离平方,如果采用其他距离但依然去最小化方差和,会导致整个算法无法收敛,所以k-means使用欧几里得方法。
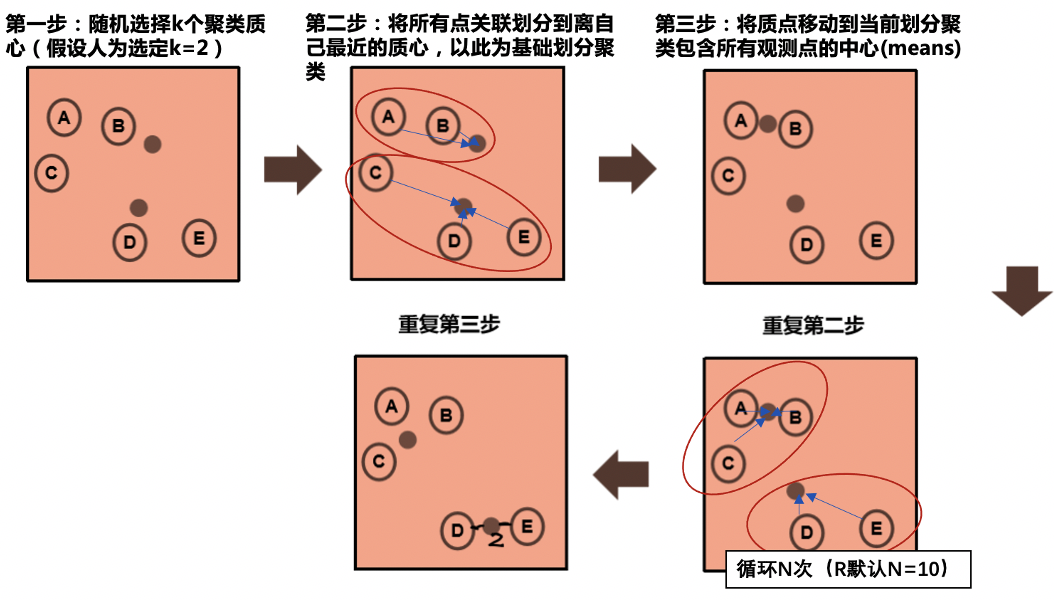
二、k-means算法原理
第一步:数据归一化、离群点处理后,随机选择k个聚类质心,k的选择下一节详细讲;第二步:所有数据点关联划分到离自己最近的质心,并以此为基础划分聚类;第三步:将质点移动到当前划分聚类包含所有数据点的中心(means);
重复第二步、第三步n次,直到所有点到其所属聚类质心的距离平方和最小。

多次随机:选择聚几类k9438手机直播中心开奖结果,则开始随机选择几个聚类质心,基于不同随机初始质心(第一步的质心)的尝试:
在所有尝试结果中,选择所有点到其所属聚类质心的距离平方和(方差和)最小的聚类方式。
三、k值选择方法
K值的选择是k-means算法很重要的一步,K值选择方法有肘部法则、拍脑袋法、gap statistic法、轮廓系数等,本篇主要介绍肘部法则及gap statistic两种常用方法。
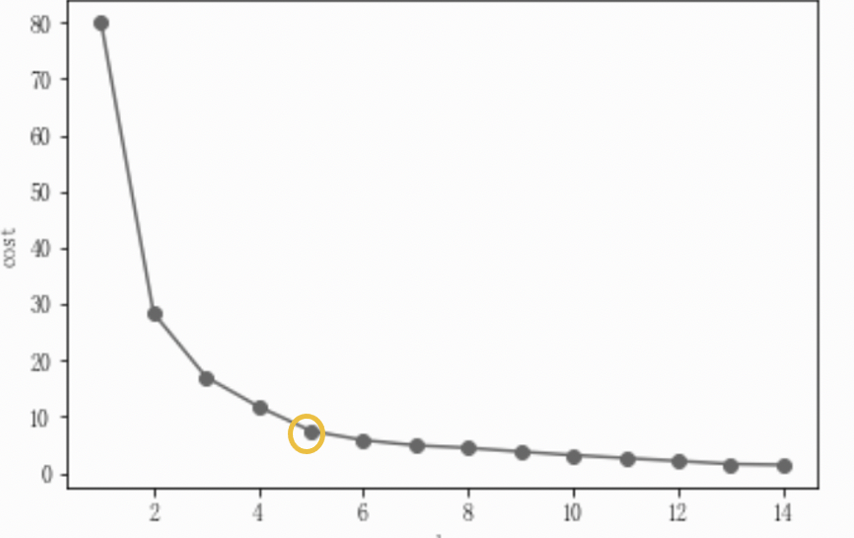
1. 肘部法则
我们可以尝试不同的K值,并将不同K值所对应的损失函数画成折线,横轴为K的取值,纵轴为距离平方和定义的损失函数,距离平方和随着K的变大而减小。
当K=5时,存在一个拐点,像人的肘部一样,当k5时,曲线趋于平稳,拐点即为K的最佳取值。
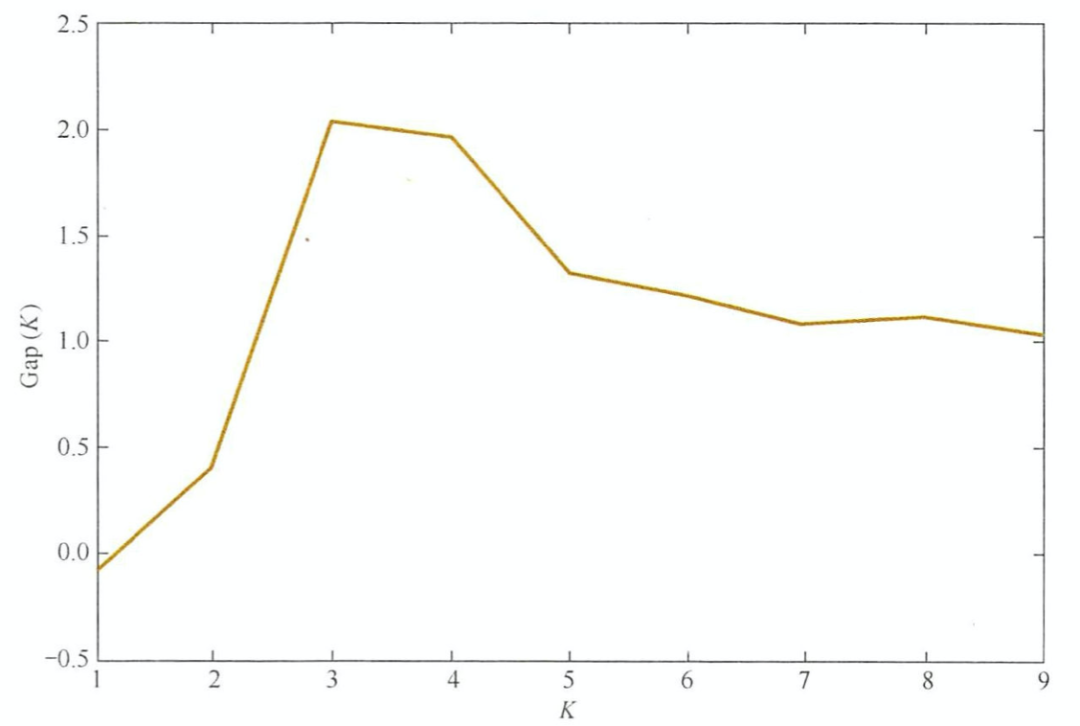
2. 间隔统计量(gap statistic)
手肘法则是强依赖经验的方法,而gap statistic方法则不强依赖经验,只需要找到最大gap statistic 所对应的K即可,我们继续使用上面的损失函数,当分为K组时,对应的损失函数为Dk,则gap statistic定义为:
这里的E(logDk)是logDk的期望,通过蒙特卡洛模拟产生,我们在样本所在的区域内按照均匀分布随机产生和原始样本数一样多的随机样本,并对这些随机样本做k-means,得到对应的损失函数Dk,重复多次即可得出E(logDk)的近似值,从而最终可以计算gap statistic。
而gap statistic取得最大值所对应的K就是最佳的分组数。如下图所示,K=3时,Gap(K)的取值最大,所以3为K的最佳取值。
四、k-means数据分析实战案例
案例背景:O2O平台为了更好地为线下店面服务,增加一个增值服务,即利用自己拥有的地理位置数据为线下店面选址,数据如下:
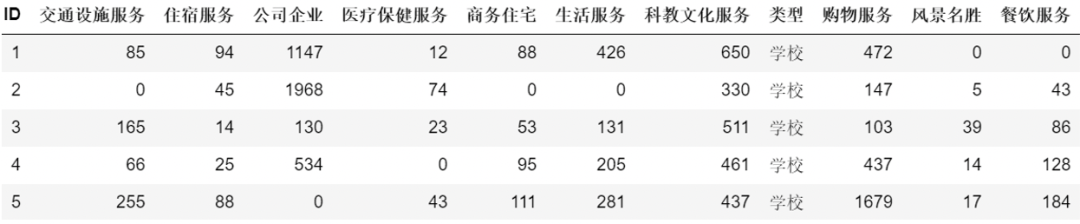
每一条数据是一个兴趣点(POI – Point of Interest)的特征,具体指的是以这个位置为中心的500米半径圆里,各类商家/设施的数量,数据中我们隐藏掉了每个POI的具体名称、坐标、类型。
选址的商家将试图从这些位置中,选择一个作为下一个店面的位置。
商家想知道这40个潜在店面位置之间是否有显著的差异。我们可以将所有POI按照相似程度,划分成几个类别?
步骤:
1. 读取数据
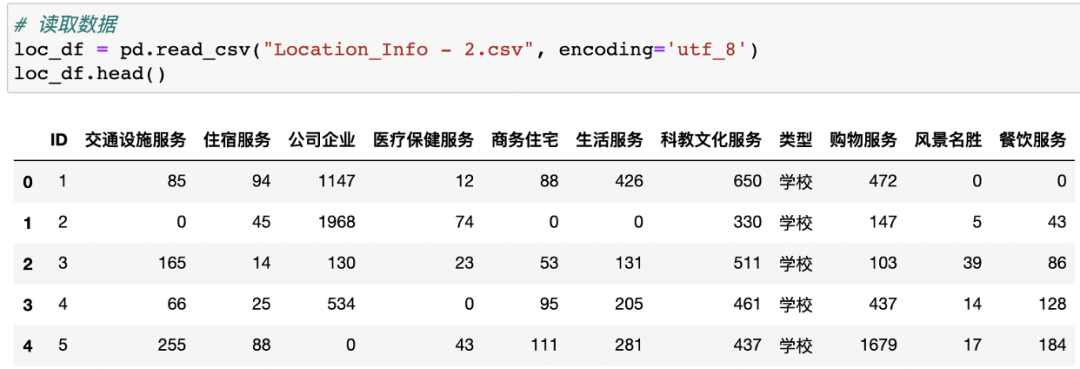
2. 特征选取

来源【抖音特训营】自媒体,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站不拥有所有权,不承担相关法律责任。如发现有侵权/违规的内容, 联系邮箱jkhui22@126.com,本站将立刻删除。



